Deepseek AI開発の費用は16億ドルで、手頃な価格の神話を暴きます
Deepseekの新しいチャットボットは、魅惑的な約束で自己紹介しました。この声明は、Deepseekが競争力のあるAI市場で達成することを目指しているものの本質をカプセル化しています。これは、Deepseekの影響によりNvidiaの最大の株価下落の1つを見ました。
 画像:Ensigame.com
画像:Ensigame.com
DeepseekのAIモデルは、革新的なアーキテクチャとトレーニング方法のために際立っています。以下は、それを区別する重要なテクノロジーです。
マルチトークン予測(MTP) :一度に1つの単語を予測する従来のモデルとは異なり、DeepSeekのMTPは、文のさまざまな部分を分析することにより複数の単語を同時に予測します。この方法は、精度を高めるだけでなく、モデルの効率を向上させます。
専門家(MOE)の混合:Deepseek V3は、256のニューラルネットワークを利用してMOEアーキテクチャを採用しており、トークン処理タスクごとに8つがアクティブ化されています。このアプローチは、AIトレーニングを加速し、パフォーマンスを大幅に改善します。
マルチヘッド潜在的注意(MLA) :MLAは、テキストフラグメントから重要な詳細を繰り返し抽出することにより、文の最も重要な部分に焦点を当てています。これにより、重要な情報が欠落する可能性が減り、AIが重要なニュアンスを効果的にキャプチャできるようになります。
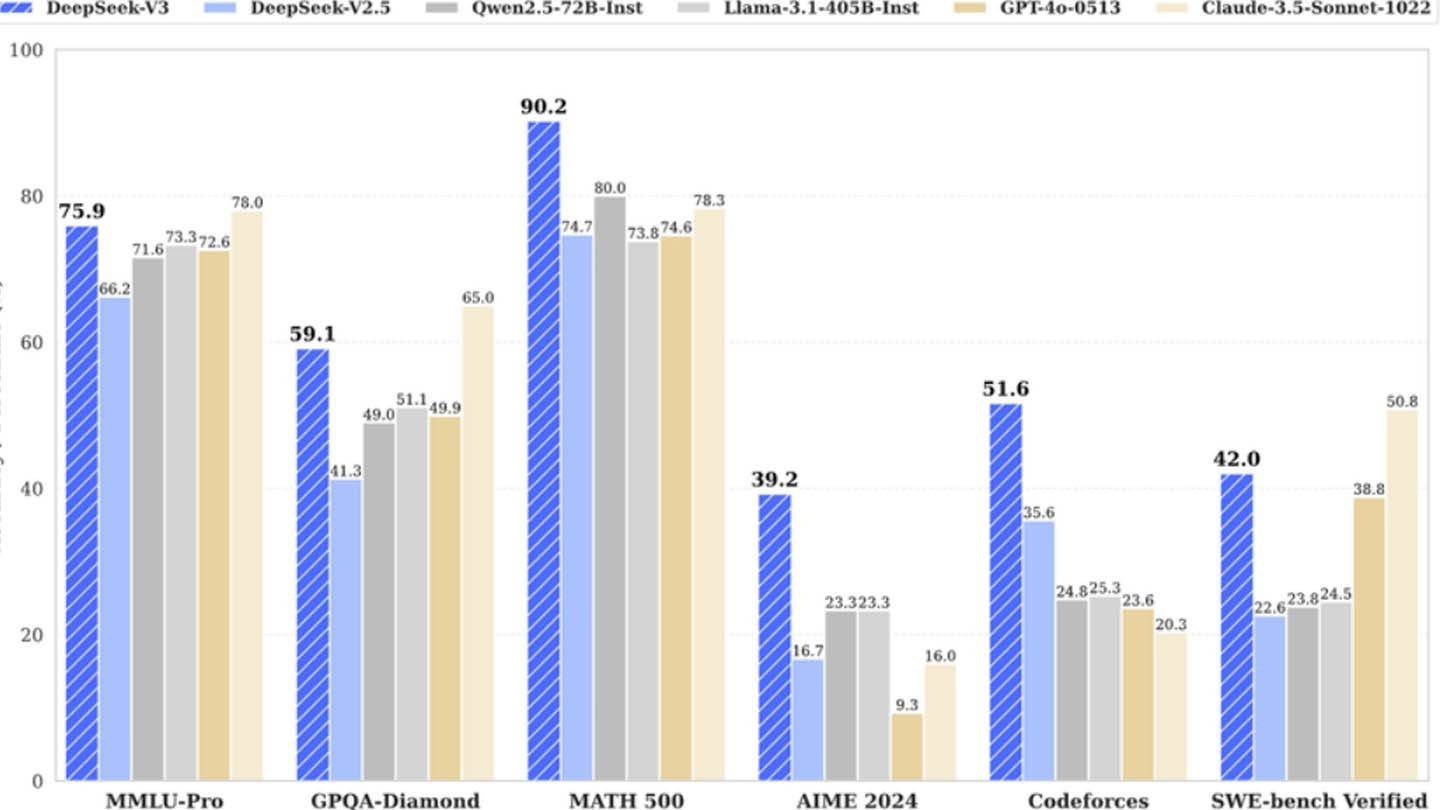
わずか2048グラフィックスプロセッサを使用してDeepSeek V3をトレーニングするために600万ドルの最小予算で競争力のあるAIモデルを開発したと主張しているにもかかわらず、さらなる調査により、より複雑な画像が明らかになりました。
 画像:Ensigame.com
画像:Ensigame.com
Semianalysisのアナリストは、DeepSeekが約50,000のNVIDIA Hopper GPUで構成される膨大な計算インフラストラクチャを運営していることを発見しました。これには、10,000 H800ユニット、さらに10,000 H100、追加のH20 GPUが含まれ、AIトレーニング、研究、および財務モデリングのために複数のデータセンターに広がっています。サーバーへの総投資は約16億ドルで、運用費用は9億4,400万ドルと推定されています。
Deepseekは、中国のヘッジファンド高飛行者の子会社であり、2023年にAIテクノロジーに焦点を当てるためにスタートアップを紡ぎました。クラウドプロバイダーに依存する多くのスタートアップとは異なり、DeepSeekはデータセンターを所有しており、AIモデルの最適化を完全に制御し、迅速なイノベーションを可能にします。同社は自己資金であり、柔軟性と意思決定速度を向上させます。
 画像:Ensigame.com
画像:Ensigame.com
Deepseekはまた、主要な中国の大学で年間130万ドル以上を稼いでいる研究者の中には、トップの才能を集めています。わずか600万ドルで最新のモデルをトレーニングするという同社の主張は、より広い文脈を考慮すると非現実的に思えます。この数字は、トレーニング前のGPUの使用のみを占め、研究費用、モデルの改良、データ処理、および全体的なインフラストラクチャコストを除外します。
Deepseekは設立以来、AI開発に5億ドル以上を投資してきました。そのコンパクトな構造は、より大きな官僚的企業とは異なり、AIイノベーションの積極的かつ効果的な実装を可能にします。
 画像:Ensigame.com
画像:Ensigame.com
Deepseekの旅は、資金提供された独立したAI企業が実際に業界の巨人と競争できることを示しています。しかし、専門家は、その成功は、AI開発の「革新的な予算」ではなく、実質的な投資、技術的なブレークスルー、および強力なチームによるものであると指摘しています。それにもかかわらず、DeepSeekのコストは競合他社のコストよりもかなり低いままです。たとえば、DeepseekはR1に500万ドルを費やしましたが、ChatGPT4Oのトレーニングは1億ドルかかりました。
ただし、競合他社よりも安いです。






























